人工智能时代下机器学习(machine learning)的相关发明与传统计算机程序发明有显著不同,究竟专利申请人在撰写该类别的专利请求项与说明书时,要如何呈现才能符合专利充分揭露要件? 本文依序从(1)该人工智能或机器学习的发明应用于或解决何种问题、(2)该发明使用何种模式结构(model structure)、(3)该模式结构使用何种算法(algorithm)施以训练、(4)该用于施以训练(training,或称测试)的算法被给予何种数据(data)、(5)该数据受何种超参数(hyperparameters)规制、(6)综合以上软件阶层如何与硬件结合等概念问题解构并说明之。

图片来源:CanStockPhoto.
美国法院将专利法第112条第(a)项的充分揭露要件区隔为「可据以实现」和「书面说明」两个独立要件,要求专利申请人于说明书应详实揭露发明内容,使所属技术领域具有通常知识者(PHOSITA)得制造及使用该发明技术,各请求项也必须为说明书所支持,所请范围不得超出说明书揭露的内容[1]。针对软件设计领域具体来看,充分揭露要件对软件发明的要求可着重于(1)检视该发明请求项是否叙述所请软件发明具备的功能,(2)说明书是否阐明如何达到前述请求项对该软件发明具备的功能划出的权利范围。
机器学习不同于传统计算机程序发明
未如传统计算机程序发明的运算机制通常可被预测和清楚描绘,机器学习会基于应用基础不同,改变运算过程中的解决方案(solution),故运算过程具不确定性。具体而言,机器学习在运算过程中并非单纯重复地处理数据库问题,其可从接受的数据或经验选取出部份予以优化,故设计者得塑造一具有算法执行的模式(model),并以不同的参数(parameters)给予独立定义;是以,所称「学习」,就是让该模式以设定的算法予以执行。通常设计者会利用「训练用数据」(training data)优化参数,等到训练用数据累积一定程度后,参数价值也因优化结果逐渐提高。换句话说,机器学习的模式是由参数所定义,参数的价值来自训练用数据的持续喂养(feed)、将之优化的结果。因此,不同的训练用的数据或不同的模式设计都将造成机器学习在执行演算后不同的最终结果。
从专利授予的角度言之,机器学习系统的开放性和其缺乏经演绎而不可预测的本质,相较于传统僵化的程序运算对适应新情境或新识别方案时执行效率都较为良好,而这些本质就直接关乎于专利充分揭露要件对请求项和说明书撰写上的要求与检核。
由于一新发明得同时符合不同机器学习的模式结构或训练用算法,故建议该发明可以该模式或算法的「功能特性」请求专利,因此在撰写专利申请时,该专利说明书需完整阐述如何达到该些「功能」或「结果」;更有甚者,由于该些参数价值来自于反复实验性操作而得以优化,因此说明书必须提供足够的解释或范例指引,以证明上述这些操作不需过度实验(undue experimentation)即可达成。
从经典判决先例出发:解决何种问题、模式结构与算法的揭露
联邦巡回上诉法院(CAFC)在1997年Genentech, Inc. v. Novo Nordisk A/S案指出,说明书应揭露包含「特定起始材料(starting material)」和「执行过程的状态或条件」[2]。此对机器学习发明来说,就是指「要被解决的问题或被使用的模式结构」和「用于优化参数的训练过程和方法」,故说明书应至少揭露适用模式的特性(characteristics)和用于训练该模式的算法,甚且若是超过一种模式或多种算法可以适用该发明,则该些备选模式或算法都应予揭露;另由于「要被解决的问题」可能限制模式或算法的设计,因此该欲解决的目标应也需要明确的指明。
在1988年In Re Wands此经典案例中,CAFC提出评估系争专利请求项是否需过度实验方能据以实现的八项因子,为避免说明书对机器学习的叙述过于抽象,其中四项因子对判定人工智能或机器学习发明的专利是否得据以实现相当关键。除发明本质(the nature of the invention)外,包含有无操作实施例(working examples)、实验所耗费的时间和金钱(the quantity of experimentation necessary)和专利申请所呈现指示或指导的数量(the amount of direction provided by the inventor)[3],在撰写说明书时都应该留意之。
施以何种训练用数据和超参数的揭露
一旦识别出机器学习的发明所实行的模式态样和训练用之算法,发明人通常下一步考虑的就是应使用何种类型的「训练用数据」。以专利说明书转写角度观之,包含数据量的大小、来源和可否接受多来源的原始数据(raw data)等因素应为适当揭露。
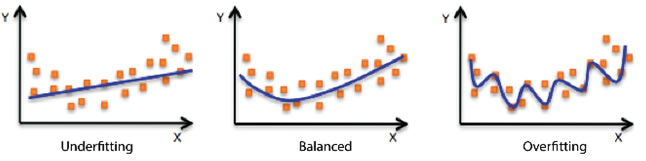
首先,申请人应注意的就是数据量的「大小」。数据量太少会造成训练数据和评估值间的预测误差,例如模式产生「低度拟合」(underfitting),此时由于模式无法撷取输入范例(通常称为 X)和目标值(通常称为 Y)之间关系模式,执行效能不佳;或产生「过度拟合」(overfitting),此时虽有良好执行效果,但模式仅能读取数据,无法一般化未知的范例[4]。数据量太多或许只需在适当时间点停止施以数据,但过程中无法获知系统内存和运算资源是否足以支撑而产生误差。
此外,申请人应考虑数据的「来源」,从公共领域直接搜集的数据并未被良好处理或标示,因此,若机器学习的发明人有特定数据的来源应予以揭露,若无指定来源,在撰写说明书时应着墨所请发明应用的数据来源或可被接受的数据特性,以利审查官或PHOSITA在阅读该专利时得以识别该来源。最后,由于特定算法仅能运行单一或处理过后的数据,若数据来自多个不同来源,则该些搜集来的资料须要先经过规范化(canonicalized),因此,所请发明可否接受多来源的原始数据也受PHOSITA注目,故应完整揭露于专利说明书。
图片来源: Amazon Machine Learning开发人员指南 (同注4)
超参数则用于规制机器学习模式对训练用数据的反应。换句话说,超参数描述机器学习模式的样貌且不会被算法执行时所影响,例如超参数控制着在类神经网络(neural network)的层数(layers)和节点(nodes)中数据的交会,因此超参数如何被设定和设定方法应该在专利说明书中揭露,甚至提出实施例。
机器学习下的软硬件结合
在软件领域的发明专利重视软硬件间的互动关系(interrelationship),因此申请人在撰写说明书时应留意勿将机器学习应用的软件和硬件各自单独描述而忽略阐述两者间关系。换句话说,所申请的机器学习发明将如何在硬件上执行:如执行时的逻辑运算为何?该执行的媒介是在当地的硬件还是传输至云端运算?……等等。甚若有特定硬件需求,均须详细的在专利说明书中揭露,以充分支持专利请求项的范围。
小结
本文循序渐进将人工智能时代下机器学习予以解构,并指出在撰写专利说明书时应注重之处,以避免未适当揭露而使所申请之发明无法据以实现或说明书未充分支持请求项范围,而导致专利申请在审查时被核驳或在执行权利时因未满足充分揭露要件而被举发无效。
备注:
- 台湾法则依专利法第26条第2项后段:「其得包括一项以上之请求项,各请求项应以明确、简洁之方式记载,且必须为说明书所支持。」,称之「支持要件」。参见「发明专利实体审查基准」,经济部智慧财产局,2013 年版,第二篇第一章第2.3.4 节,第2-1-31 页。
- Genentech, Inc. v. Novo Nordisk A/S, 108 F.3d 1361 (Fed.Cir.1997) (“the specification should disclose specific starting material and the conditions under which a process can be carried out.”)
- 其他四个因子分别为既有的技术水准、该领域中相关之技术、该技术是否具有预期性、申请专利的范围。In Re Wands, 858 F.2d 731, 737 (Fed. Cir. 1988).
- 模式拟合:低度拟合与过度拟合模型拟合,Amazon Machine Learning开发人员指南,Amazon Web Services, Inc.,https://docs.aws.amazon.com/zh_tw/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html (最后浏览日期:2019年4月20日)
好消息~北美智权报有微信公众号了!
《北美智权报》内容涵盖世界各国的知识产权新闻、重要的侵权诉讼案例分析、法规解析,以及产业与技术新知等等。
立即关注北美智权微信公众号→ NAIP_IPServices
~欢迎读者分享与转发~ |
 |
|
【本文仅反映专家作者意见,不代表本报立场。】
 |
|
| 作者: |
李秉燊 |
| 现任: |
美国杜克大学法学院访问学者 |
| 学历: |
(台湾) 交通大学科技法律研究所博士生
(台湾) 交通大学科技法律研究所硕士生(径升博士班)
(台湾) 阳明大学医事技术暨检验学系硕士 |
| 专业资格: |
2018年度台湾专利师考试及格
2014年度台湾医事检验师考试及格 |
|
|
|


