标准必要专利SEP(Standard Essential Patents)的「制度」已经行之有年,特别是在通讯产业,俨然已成为专利授权、侵权损害赔偿的主要价值计算标准。为了防止厂商利用SEP来变相独占市场,FRAND – 一种号称公平合理的授权原则应运而生。然而,SEP只是一种宣示机制,并没有经过审查与认证,在遇到授权金或损害赔偿计算时更是一场耗时耗财的拉锯战。为了克服人类审定SEP的不足之处,IPlytics提出了让AI来进行的可能性。

图片来源 : shutterstock、达志影像
标准必要专利包含了两个重要的元素,一个是「标准」,一个是「专利」,然而,这两个元素是背道而驰的。「标准」在每一种产业都是必须的,为的是要把市场做大,因为唯有标准的存在,不同厂商所生产的设备器件才能兼容,进而互通互联,这样市场才能大规模扩展。标准的重要性在通信产业尤为明显,如果没有标准,不同厂商都有各自的规格,全球的通信产业肯定是无法像今天这样蓬勃发展的,早期日本的PHS无疾而终即说明了这个道理。然而,「专利」在一定程度上是对市场的一种限缩,因为专利权是政府相关部门向发明人授予的在一定期间内限制他人生产、销售或以其他方式使用其发明的排他权;有「独占」意味。
简言之,一个标准的成功在于它的广泛传播;它的价值在于它的广泛使用。这与专利形成鲜明对比,专利是建立在排他性上的消极权利。与标准相反,专利的价值来自于它的力量尽可能排除第三方使用它;除非第三方愿意为其使用付费。这就是标准和专利之间的固有矛盾,这种紧张关系在标准必要专利中尤为明显。一项专利被宣示为标准的必要条件后,该公式可能在专利所有者手中积累特殊的市场力量,同时使获得专有技术的成本可能变得非常昂贵,而FRAND (公平、合理和无歧视性)的承诺也因此被引入。
SEP和数据宣示的限制
表面上,FRAND解决了SEP授权金、甚至是损害赔偿的计算问题,但事实上,SEP的底层「认定」问题却一直无法解决,这个问题在侵权官司中更是严重。对SEP稍有认识的人都知道,SEP是发明人及专利权人的一种自我宣示机制,然而,那些包括ETSI (4G / 5G)、 IEEE (Wi-Fi)、及 ITUT (HEVC/VVC)在内的标准制制定组织 (Standard-setting Organizations, SSOs) 并没有去确认及更新这些由发明人及专利权人自我宣示的信息,因此,在授权谈判、专利收购或诉讼过程中,那些专利是必要的,那些不是必要的问题,便成为了谈判 SEP 组合价值、或侵权损害赔偿时争论最多的问题之一,双方在此一议题上都必须耗上大量金钱和时间。
SEP除了没有公定的标准可以遵循外,也没有公认的宣示原则。有一些SSO像是ETSI鼓励标准开发者宣示任何可能与标准有关系的专利(Maximal declaration situation)。虽然有少数公司在宣示专利之前会制作权利请求图表(Claim Chart),但也有许多公司则在未进行任何深入分析的情况下即宣示任何潜在的专利。此外,也有不少公司会在专利未决(pending)时即宣示专利,而标准这时候也正在发展中。因此,不管是专利权利请求或是标准规格,都极有可能会在初始宣示后产生变化;而根据宣示的信息所实践的设计中,其中一些宣示的专利最终可能不是「必要」的专利。
另一方面,一些SSO像是IEEE(特定Wi-Fi标准的组织)和 ITU(特定HEVC/VVC 的组织)允许专利所有人提交所谓的一篮子(blanket declarations)宣示,其中不得宣示特定的专利号,也没有宣示关于潜在必要专利的任何进一步细节。换句话说,所宣示的信息是相当不透明的。
总结以上所提,自我宣示的SEP有两个大问题:并非所有被宣示的专利都是必要的,也并非所有的必要专利都被宣示了。这显示了被宣示的SEP数据需要细致化、过滤、推断,从而建立中立和客观的SEP确定和估值指标。IPlytics的CEO Tim Pohlmann认为这一工作之繁复已超越人类能力范畴,除了因为全球范围内被宣示的SEP数量庞大外,人类也很容易因为技术背景、经验及立场不同等等因素而造成偏颇。
由人类来测定SEP的局限
為为了说明由人类来测定SEP的限制,Tim Pohlmann举了TCL v. Ericsson的例子[1][2],来说明雇用人类专家来计算、评估和确定整体必要性比率时所存在的局限。在此诉讼中,Ericsson和TCL 就Ericsson的SEP专利组合的质量和必要性与 2G、3G和4G SEP的总数有一些争论。TCL委托了主题专家 (subject matter experts, SME) 对 2,600 件于 ETSI 宣示的2G、3G 和4G专利的随机样本进行研究,以确定必要性比率,然而,此一对必要性的评估方式遭到一些批评。
Tim Pohlmann指出,据计算,受委托的专家每项专利平均必须花费大约20分钟,并且平均每项专利的评估费用为100美元;为此一诉讼案件确定(determine)SEP所花费的时间和支付的金额与验证 (verify) SEP 所收取的费用大不相同。因此,大多数专家都同意,质疑人类是否可以在短短20分钟内将一项专利与复杂的技术规范进行对比,以确认此一专利的必要性比例;因为这些技术规范可能多达600页和数百个单元。然而,另一个更普遍为人诟病的地方则是专家的偏见,TCL所聘用的专家理所当然知道自己应该站在那一边。
TCL v. Ericsson的案例说明了由人类来确定SEP存在两个主要缺点:
(1) 根据复杂的标准(例如 2G-5G、Wi-Fi 或 HEVC)对数以万计的被宣示的SEP 进行彻底对比所需的预算和时间浩大,就经济层面而言是不可行的。
(2) 人类专家偏向于「己方」(通常是出资的一方)。
SEP的复杂性
利用人工来确定SEP是既耗金钱又费时的,主要是因为标准化技术的复杂性。像5G这种标准是由一千多个技术规范 (Technical Specifications, TS) 所组成的,而这些TS可能有多达600页和数百个章节。如果要确定被宣示的专利是否与标准相关,专家们必须研究并理解所有的专利权利要求,并将已识别的权利要求元素与所有可能的标准部分进行对照。更重要的是,一项专利可能会被宣示为多个标准文件,在对照专利权利要求时也必须考虑这些标准文件。以下图1及图2说明了SEP数据的复杂性。
图 1:多个标准的SEP宣示(ETSI SEP 数据库示例):

图片来源:IPlytics
图2. 被宣示的SEP及标准的全部组合

图片来源:IPlytics
图1和图2说明了仅考虑ETSI宣示数据时,提交给多个标准文档的专利宣示数量就产生了近200万种组合。而且每个ETSI标准规范的每个文件平均有212个所谓的标准部分,并且每个申报的专利平均有20个权利要求项,「1,778,400 x 212 x 20」的权利要求有超过75亿个已宣示专利的权利要求和标准的组合。Tim Pohlmann指出这样的数据数量是人类无法驾驭的。
用计算机为专利必要性评分
倒排索引 (inverted index) 数据结构是典型的搜索引擎检索算法的重要部分,可以快速全文搜索和文本比较,互联网搜索引擎即是一个好例子。如果利用这种技术来进行专利比对,当索引部署在高度可扩展的云计算上时,索引、搜索和比对甚至可以在几毫秒内完成数十亿个数据点,像是比对专利权利要求和标准部分数据。Tim Pohlmann指出最先进的语义算法使用的技术将文档表示为术语空间中的向量,允许比较专利权利要求和标准部分的实际内容,而不是单纯的关键词的重迭,如图3所示。
图3. 请求项比对标准之语义分析
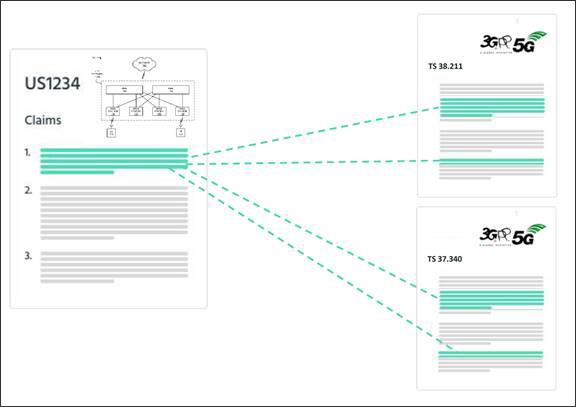
图片来源:IPlytics
当然,权利要求项所使用的语言和标准说明书中的语言通常很不一样。专利权利要求是由专利代理人使用广泛的术语起草,以便权利要求适用于尽可能多的应用,一方面又被视为有法律效力的法律文件;而标准规范则是由开发标准并使用非常具体的语言的技术工程师来编写。为了克服这个问题,语义模型使用了人工创建的权利要求图表样本进行训练,以了解权利要求和标准的上下文,其中算法可以学习识别专利权利要求元素的某些概念的不同表达。
除了专利权利要求和标准部分的语义比较之外,计算机的算法可以透过将专利列出的发明人(姓名、单位)对比相应标准会议的参与、或透过对比专利的申请人/受让人所接受的与宣示标准相关的标准贡献。研究人员发现,当发明人出席会议时,参与的公司在这方面影响最高。图4为专利发明人与标准会议参与之间的相互关联的证据。图4采用了IPlytics平台来交叉分析了关联发明人参与 3GPP会议宣示5G专利组合的情况,数据显示平均 72% 的 5G 宣示专利的发明人(名字、姓氏、实体)参加了相关的5G 3GPP标准会议,讨论了申报的技术规范。
图4. 排行前面的SEP宣示公司至少会派一名被宣示专利上列名的发明人参加相关工作小组的会议
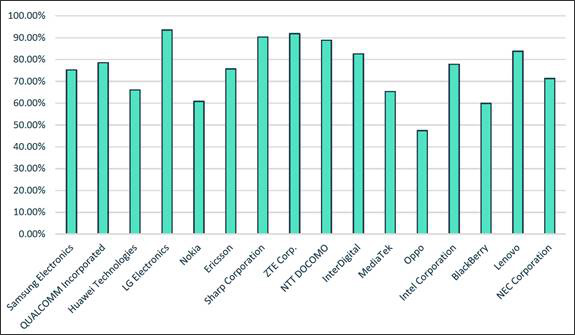
图片来源:IPlytics
用AI来协助确定SEP
建基于AI人工智能的语义权利要求部分比对和与发明人参与的交叉关联,以及在标准会议上提交的技术贡献度,是专利与标准有关联性的有力指针,并且可以作为特征集成到人工智能的SEP预测模型中,对专利进行评分,以测定其成为SEP的可能性。虽然利用AI来确定SEP可能无法完全取代专家的工作,但AI确定可以协助评估和确认SEP,让企业可以节省不少金钱与人力,且结果也较为客观。
参考数据:
- Using AI to Valuate and Determine Essentiality for SEPs, Tim Pohlmann CEO IPlytics, June 2021
备注:
|



